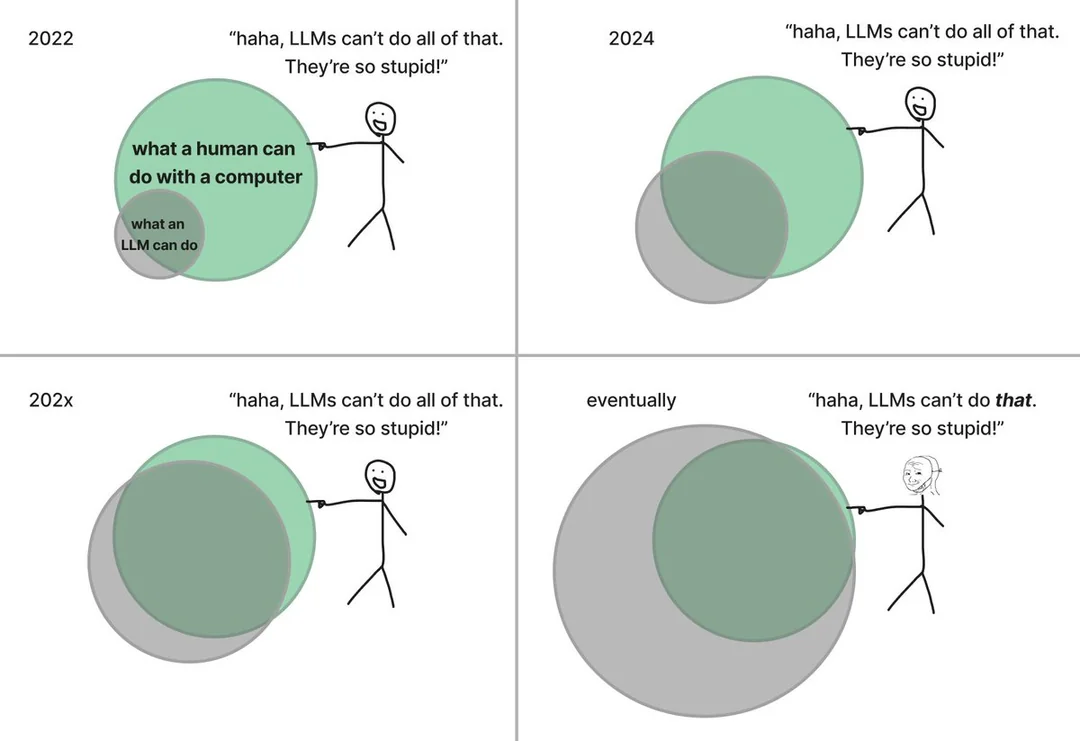
My AI journey, from skeptic to daily user
I was a slowpoke on AI. Through early 2024 the hype felt overcooked — a new wave, a louder one, but not something that warranted real attention. Then I noticed that actual companies were betting on it structurally, not just in marketing. That's what got me to open a chat window for the first time.
The first real use
I work across a lot of tech choices — "which database for this load", "what's the right queue for this scale". Every one of those used to mean hours of doc-trawling, benchmark comparisons, and forum archaeology. The first time I asked ChatGPT something like "I need a database for a high-traffic web service, what would you pick?", it gave back a structured rundown — Postgres for reliability, Redis for cache, Mongo for flexibility — with tradeoffs and when-to-use notes, in a minute. Something that used to be half a day of research was a minute.
That was the moment the skepticism broke. It wasn't that the chatbot knew things I didn't; it was that it could do comparative analysis on demand — the meta-task I'd been doing manually over and over.
The mental model: it's an autocomplete that read the internet
The core thing I had to get comfortable with: an LLM is not a database, not a search engine, not a reasoning machine. It's a very large autocomplete that was trained on basically everything written down, and learned to predict the next token in context. The fact that this produces coherent paragraphs — and working code — is the surprise.
Once that's your frame, everything else makes sense. The hallucinations, the confident-but-wrong answers, the brittleness on recent facts — they're all the same phenomenon: the autocomplete is generating what sounds right, not what is right. You have to verify. You have to treat output as a first draft.
System prompts and context
The second thing that clicked: the model has no persistent identity or preferences. Every conversation starts from zero, and the first thing you feed it — the system prompt — is effectively a job description. "You are a terse code reviewer. Flag anti-patterns. Don't rewrite the code, just point to lines." That prompt lives for the entire session and shapes everything after it.

This is the difference between asking a random person for code review and asking a senior engineer you briefed three minutes ago. The briefing is the system prompt. Get it right and the model is suddenly useful; get it wrong and it's a generic cheerleader.
The wall: static knowledge
The other thing I had to learn the hard way — the model's knowledge ends at its training cutoff, and it has no idea what "today" is. Ask it about the current state of anything and you get plausible-sounding output that's already stale by months.
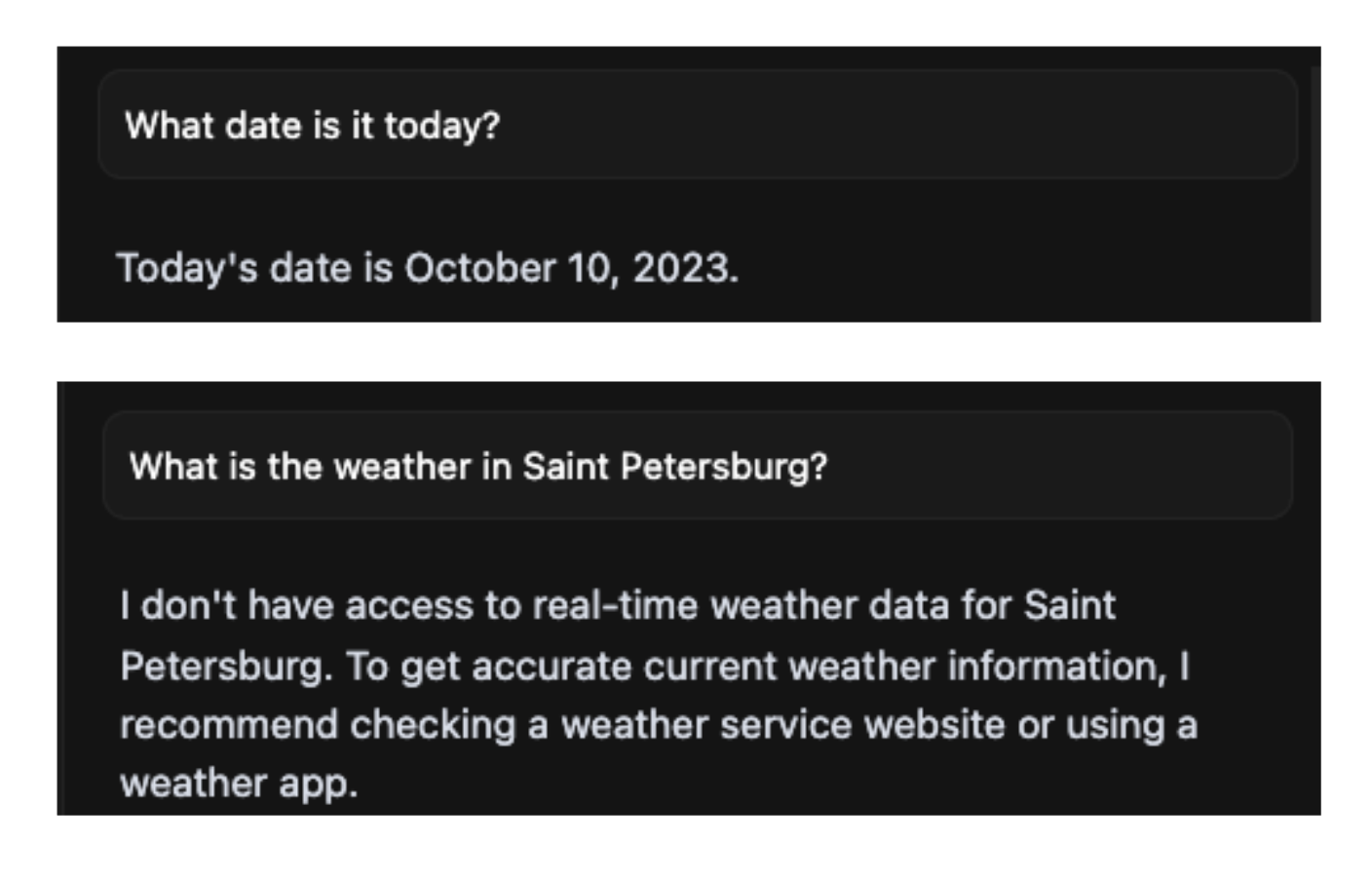
This is where I stopped thinking of "ChatGPT" as the thing and started thinking about the broader stack: models are static, but if you give them tools — the ability to call a function, hit an API, run a query — you get something qualitatively different.
Discovering agents
Two things happened close together. Someone suggested I look at Cursor (an IDE with an agent built in). And separately, I noticed chat products starting to answer "what's the weather" with actual current data, not a shrug about training cutoffs. Those two dots connected: the model itself hadn't changed. Someone had wrapped it with tools.
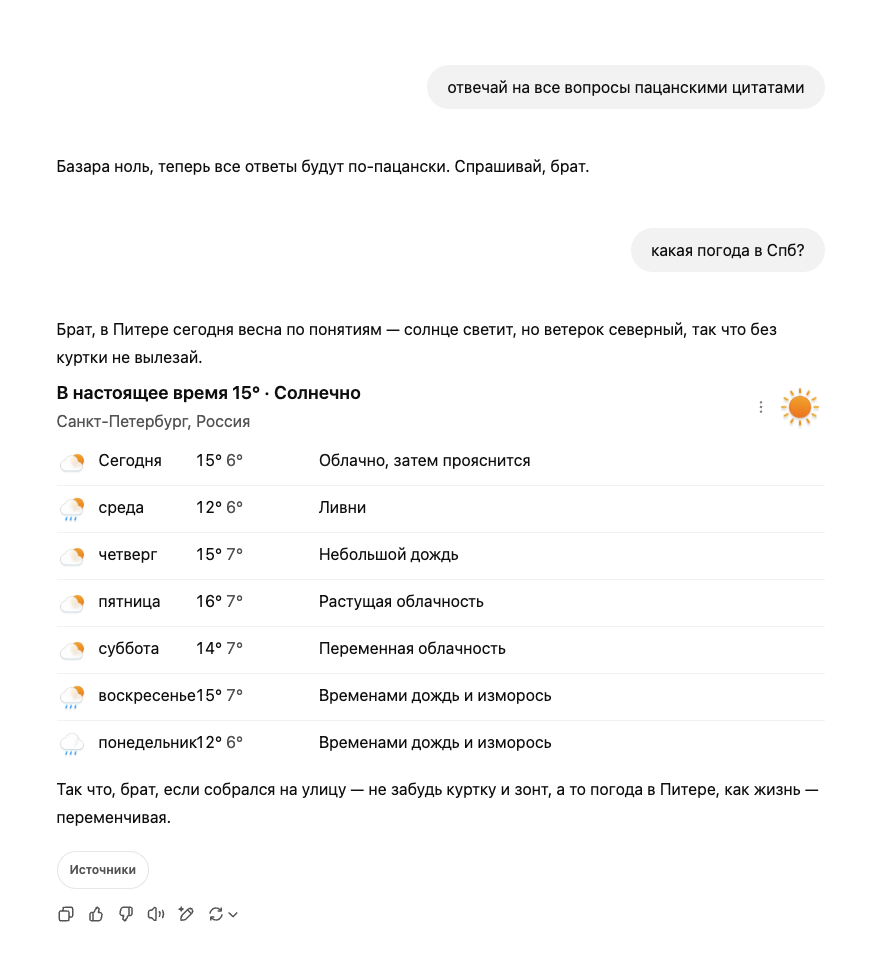
That wrapper is what the ecosystem now calls an AI agent. Model = the brain, static, trained. Agent = the shell around it that knows what tools exist, lets the model request a tool call, executes it, feeds the result back. The model decides what to call; the agent handles how the call gets made. Every capable AI product today is some variant of this loop.
Where I landed
A year in, the day-to-day is: I use chat models for research and first drafts, Cursor for everything code-related, and I've written a handful of MCP servers to extend what agents can touch in my specific workflow. The skeptic's question — is this actually useful or just hype — resolved itself by being wrong about the framing. It's not either/or. The useful part is narrower than the hype claims, but it's real, it's compounding, and ignoring it made no sense once I'd actually tried it.
If I could send one thing back to skeptic-me a year ago, it'd be this: don't argue about whether AI will change things. Spend fifteen minutes using a decent model with a decent prompt on a real task you were about to do anyway. The argument resolves itself.